

In my last post I introduced the RIDE (R1D3) Framework for Active Defence. I outlined there the four basic phases of an active defence pipeline: Research, Discovery, Disruption and Development. In this article, I will describe the first phase (the R in R1D3) in detail. I've scheduled this Part 1 to be released today and Part 2 is already scheduled for next week ;)
Research is the entry door into our active defence pipeline, which has huge downstream ramifications. If our initial research is inefficient, we will significantly reduce the likelihood of influencing security control uplifts in subsequent stages.

In our Research Phase, the most important question we want to answer is one about information meaning or significance: what does this cluster of data mean within the context of my organization and how does it inform actionable outcomes? What I describe abstractly as "a cluster of data", refers to any information that arrives to us in a structured or unstructured manner, though the majority of times it is unstructured: a threat report, a summary of intel provided by a trusted party, information about an attack suffered by a company in the same industry vertical, etc. The reason it is unstructured is that the majority of threat intel globally is produced for the consumption of human brains and not machines. We have already covered this topic in detail Part 1 of The Problem of Why: Threat-Informed Defence and Part 2 of The Problem of Why: The Uncertainty of Intelligence and the Entropy of Threats.
There are different semantic layers to data and information. These layers are not necessarily interoperable: what has significance for a machine learning algorithm is not computable by a human brain. This is why information about threats still exists in unstructured shape as text that can be interpreted by our human eyes and brains. It has to because we make decisions in a very different way to the way machines do. However threat information in its "human-readable" shape suffers many limitations, our implicit schemas don't scale well and perform poorly in big data contexts.
We go back to our initial question: what does this "x" or "y" data cluster mean for you? what is the significance of it? Information needs to be able to direct and influence the behaviour of the business to improve security controls that ultimately protect the revenue streams which are the very core of its existence.
The problem is not cyber threats

You may be tempted to assume that the problem of threat-informed defence is about cyber threats. But what is a "cyber threat"? Common lore tells us a cyber threat is the crossover of intent + capability + opportunity. Let's for a moment accept the current industry heuristic and consider a cyber threat as a construct that has the three variables stated above. This concept means nothing if we cannot link it to data. The problem of threat-driven cyber defence is not about threats, it is about our knowledge of this construct we call a "cyber threat": what are the discrete datapoints in which it is represented in our internal systems? STIX is an example of a framework that aims to answer that question but solely from the modelling perspective. The problem of cyber threats is about data semantics and our model's descriptive power: our ability to map feature rich data from the complex domain of world events to the domain of cyber defence operations.
This data semantics problem can be summarized in the five dimensions of information significance. There is a great paper that is the result of a thorough literature review about the topic: Threat Intelligence Quality Dimensions for Research and Practice. The authors examine the dimensions of data provenance, relevance, interoperability, reliability, actionability and timeliness. Information significance is, in other words, the process of meaning extraction from feature rich data of high dimensionality. How to design a data pipeline that is efficient at extracting meaning from your threat intelligence data?
Enter the Active Defence Research Data Pipeline 🕵️♀️
I really need diagrams to better express the mental models I'm thinking about so here's the diagram that represents what we are going to talk about today:
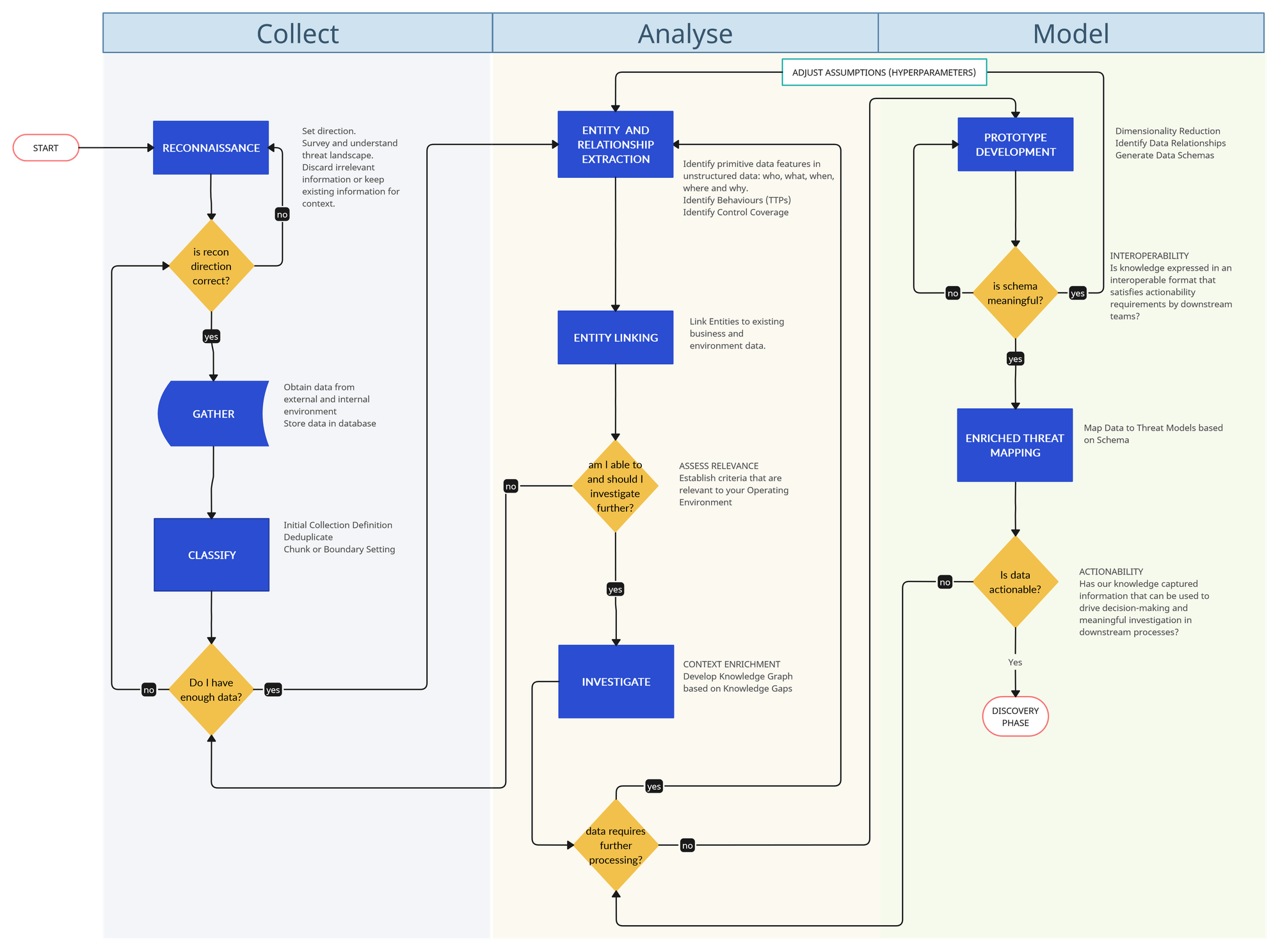
A brief note about our design principles:
- The whole pipeline workflow is built to resemble the concept of a self-learning knowledge graph.
- My journeys into machine learning on the one side, and investigation methodologies on the other, have made me realise that both worlds share many commonalities.
- The research phase of R1D3 relies heavily on the concept of modelling our information into practical and usable schemas. I'm not talking here about threat modelling frameworks like STRIDE, PASTA, DREAD, etc. I'm referring to data schemas that help extract meaningful intrinsic relationships and workflows that help map the fields and properties in our schema to relevant security operations activities like threat hunting, detection engineering, adversary emulation, etc.
- Automation and DevOps readiness are other guiding principles for this model. Please consider that many steps in the pipeline are automatable to a degree. However, not everything is nor should be automated.
- Organic-brain computing by us humans is still very much required for the difficult work of integrating the depth of contextual layers of your business' ever-evolving environment: "It is important to note that all intelligence analysis is generated by a human" (Intelligence-Driven Incident Response, p42)
Diving into the Components of R1D3 Research Pipeline 🌊
We will approach this following an example, and building a schema as we go along. We will utilize Microsoft's report on Volt Typhoon as an example.
Collect 🔍
Step 01: Reconnaissance 🧭
The Cyber Kill Chain model has indoctrinated us into believing that reconnaissance is an activity that merely relates to offensive security. However, at its core, it is really all about building a more comprehensive situational awareness. The recon phase loosely aligns with the stage of "planning and direction" in the classic threat intelligence lifecycle. You will ideally leverage internal or external threat intelligence teams to provide the information that you need. There should be an initial set of questions here that will act as rough direction requirements.
Step 02: Gather 🧲
Our gathering stage is what loosely aligns with the "collection" phase of the classic threat intelligence lifecycle. Our objective is to obtain telemetry, observables or more refined products like threat reports. Gathered data has to be stored somewhere for later processing and review
Step 03: Classify 🏷️
As information arrives in our research pipeline, we need to apply some initial labelling of it based on coarse primitive categories that can be adjusted later on. This activity will constitute our first metadata layer. Our primitive categories create initial boundaries that help segregate distinct data and group similar data. It is our initial attempt at classification. There are three important actions happening here:
- define some coarse initial labels for your data like whether the information was obtained from external or internal sources, whether it is in a structured or unstructured format, whether it was self-sourced by the team or some other team provided it, what date was received on, etc. These initial tags need to be meaningful in the context of your operating environment
- after initial coarse classification apply some boundary logic that decides what is part of the same or different information, i.e. if you received multiple threat reports at different points of a week about the same topic, should they be considered part of the same body of work for downstream processing purposes? At a quick glance, what are the chunks of information that contain the most valuable aspects for consideration, i.e. where should we focus our attention in the next step?
- if we have received multiple reports from different sources that are exactly the same, attempt to deduplicate or discard duplicates
Applied to our Volt Typhoon example, using some sample data from the report, we could imagine our schema so far looking like this:
# Metadata for Initial Threat Intel Classification
source:
type: # Internal, External
example: # Threat intelligence vendor report, OSINT research
structure:
type: # Structured, Semi-structured, Unstructured
example: # Structured threat feed, CSV file, Natural language text
origin:
type: # Self-Sourced, Third-Party
example: # Produced by your own team, Received from partner
timestamp:
type: Date/Time # Use a consistent format (ISO 8601 preferred)
example: 2024-04-19 10:35:00-07:00
focus_areas:
type: # List of free-form text tags
example:
- stealth
- living-off-the-land
- credential theft
- network devices
report_hash:
type: # A standard hash algorithm (MD5, SHA1, etc.) used to hash sections of the report which can later be used to deduplicate or find similarities among diverse reports
example: 8d7dd54b6b28d95f2504b46c015b5846
Next Steps
In the next article, we will continue exploring the "R" of R1D3 framework and will expand on the Analysis phase, touching on Entity and Relationship Extraction, Entity Linking, Investigation and the tip of the iceberg around Model prototyping. The key point we will address will be this weird motto I came up with: Develop your Knowledge Graph from your Knowledge Gaps
Originally, everything was squashed into a single article but it ended up being like 6000 words long and you wouldn't stay with me that long even if I paid you!
Have a great week and please drop your comments in the section at the bottom of the page, and let me know if you would like more or less like this 😃