

Some time ago, I had a realisation: an alert is essentially internal threat intel.
This led me to the next more profound realisation: any refined information about the risks to your systems and data is intel.

Wait a second bro, are you saying that the kinds of alerts you create with detections are intel? Yes, I'm talking about the types of notables, warnings, observables or alerts that an EDR or SIEM would raise. An alert is:
- a claim about the state of events in a system
the claim can be true or false but it is an interpretation of abstract data interactions, raw data logic doesn't have meaning in and of itself - a state of events that is significant enough to be highlighted, indicating a departure from the expected or desired state of a system
so that it can inform some action - information that normally requires validation, triage and analysis
if human brain attention wasn't required, it wouldn't be called an alert, it would simply be a fully automated logic chain - information that is normally enriched with added contextual information
to build a situational awareness graph
Threat Intelligence is:
- a claim, or combination thereof, about a state of events in a system
the "system" happens to be the wider internet with all its nebulous presence, we call it the "threat landscape", the claims we make about this can apply or not to your environment, and they can be true or false (not all intel is equally accurate) about the state of affairs it describes, but it is an interpretation of observed data - a state of events that is significant enough to be highlighted, indicating a departure from the expected or desired state of a system
a potential or realised breach to the confidentiality, availability or integrity of data, perpetrated by threat actors, that indicates a significant enough departure from a desired state of the world conducive to peaceful business (something signals danger and hits the business risk thresholds: "too close to home"), as such it aims to inform some action - information that normally requires validation, triage and analysis
if human brain attention wasn't required, it wouldn't be called threat intelligence, it is us hominids that experience this perceptual construct called a "threat" - information that is normally enriched with added contextual information
threat intel is a knowledge graph that is more or less enriched and informs situational awareness
I'm sure there are many flaws in my analogy, but beyond the commonalities and differences you may find too, the point of this realisation that slapped me in the face like a rogue frisbee on a windy day, is that intel is refined information about a state of affairs (be it systems, people or data) that eventually should drive your controls.
Intel should slap you in the face.
(gently of course, unless you are doing everything wrong).

What happens in the middle?
For a lot of us, intel somehow finds its way through the many nooks and crannies of our pipeline and ends up doing some good stuff:

But as I've highlighted before here and here, it is hard to know what is in the middle. We know what we want: to lower the operational risk of doing business for our companies, institutions, NGOs, etc. What's not clear is this: Which are the many interacting pieces that make this happen? Where are the chokepoints? Where is the friction? How efficiently is data pushed through the pipes? And finally, what is the insight that it generates?
In my many adventures into Active Defence, you've seen me enter a few mazes, unravel a few knots and unfold a new pathway to understand the relationships between threat intel, data pipelines, hunting, detection and deception. I've noticed a stable pattern across all these incursions: a holistic view of operational data workflows.
I'm not talking about data merely in terms of logging telemetry from your systems, debugging information for your software, or capturing metrics, I'm talking about the underlying operational architecture of how your data, no matter the source, is converted into actionable insight, enriched at each step of an interconnected web of streams that pull the right levers.
It is a meta-data layer of sorts, something that helps you keep your finger on the pulse.
A data-centric organization does not structure its data pipeline around existing functions but redefines the functions around the data pipeline (like in Threat Hunting vs Detection Engineering: The Saga Continues).
It's all about data.
And data is about people.
If you cannot design, capture and monitor your pipeline in a way that is driving risk reduction and security control uplifts, all of it with a DevOps approach, then it will be hard to measure how intel translates into impact.
An Approach, the Git Way
So what is the best approach? What should your pipeline look like? I came up with a few heuristics that might assist in the design process.
- Intel and Impact Driven: based on the profiling and continuous collection of information for the most important threats to your organisation, and clearly articulating how these threats drive impact by mapping them out to your risk or control areas at the other end.
- Threat Modelled: the ability to translate your existing intel into concrete attack paths that can compromise your assets or data based on all the nuances of your specific environment (and not just generic intel).
- DevOps Centric: a measure of automation readiness and your ability to scale operations at machine speed.
- Three to Five Key Milestones: the points in your pipeline where you keep your finger on the pulse, the stages that give you an indication of the state of information at a point in time, metrics should capture key risk and performance indicators at each stage.
- Fractal: anywhere you look in your pipeline, at any milestone, you should be able to zoom in and find another pipeline that feeds the original milestone.
We can forever argue whether these heuristics are good or bad, but the point of a heuristic is that it works as a collective and battle-tested mental shortcut our brains use to simplify complex situations and make decisions more quickly (they can also lead to bias by the way, so always reflect later on your quick decision).
I am not sure if these rules of thumb above work for everyone else, they do for me. But my main problem has always been: how to visualize this pipeline? We are sensorial, and I don't know about you but I understand a topic much better when I can visualize it.
Is there a concept that can shape the mental model needed to even think of how a data-driven intel-to-impact pipeline should be represented? I've been searching for this for quite some time and until recently, my best option was a fishbone diagram style:
However, something was missing because different teams or functions have dependencies on each other, before even feeding the main pipe.
The graph would look weird when representing these dependencies along the timeline of the main pipe:

Finally, my inner DevOps gnome realised the answer was simpler than anticipated: you need to think of your data pipeline as a Git commit pipe and your team as a Repository.
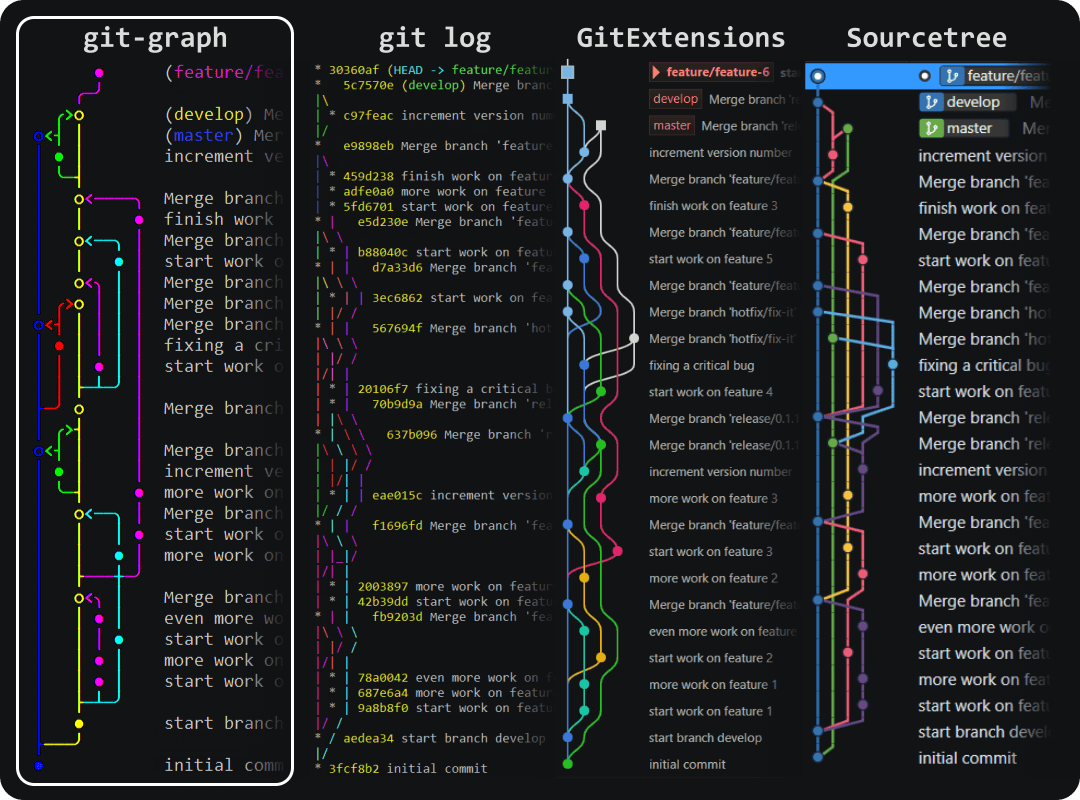
Whoa, hold on! Git? Repositories? Is this getting too weird?
Don't worry, it's simpler than it sounds. The true power lies in how it mirrors the way a successful data pipeline should function in a data-centric organisation, like a well-oiled code-merging machine!
it doesn't matter whether you are an "operational" function or not...
Think of it this way: each team in your cyber organisation is like a branch in a Git repository. Your IR team has their branch, your Detection Engineering team has theirs, and so on. Each branch is working on its own BAU workload and features, gathering unique data, and generating valuable insights.
Now, imagine your main data pipeline as the "main" branch in your repository. Just like developers merge their code changes into the main branch to create a final product, each team "merges" their data and insights into the main data pipeline, at different stages of the pipeline.
The end goal? to create an impact on the opposite end of the pipe, where you influence your risk and control areas.
Now, think of your team or function as a "repository" – a central hub where all these changes are stored and shared. This means everyone is on the same page, working together towards a common goal.

You have different Merging points where a function or a team's output plugs into another team's input at a certain point in the pipeline, effectively merging their operative outcomes with another team's operative input, triggering a process on their side.

At different points in the pipeline, you can keep your finger on the pulse by capturing and reporting on some metrics that are meaningful to you. Each function or team can have their own and you can come up with merged stats for the main pipeline:

While Git's ability to rewind is cool, that's not the real magic when it comes to building a data-centric organization. By conceptualising operations this way, we are not saying you can go back in time, but that your operational pipe becomes a DevOpsified version of itself.
Applying it to R1D3
Remember R1D3? Let's use that framework as an example of how we can apply this "Git" thinking to your operations model.
We could draw the main stages of R1D3 in the main pipeline, and then we can imagine how some teams or functions would contribute to it at different points in time.

The main things to notice in the above diagram are:
- It's just a model, and as I always echo: all models are wrong, some models are useful
- A function like Intel obtains real-time data from the DFIR & Monitoring function based on analysis of signals
- Modelling done by Intel analysis feeds into your Discovery phase where people like your threat hunters could be working their magic
- An imagined Vuln. Management function would feed their assessments of the system's landscape to your Discovery phase too
- Your DFIR team will contribute and merge their efforts directly into the Disruption phase
- Eventually, all teams converge at the Development stage where insights are translated into impact by materially improving your controls
- Your pipeline works in terms of "Releases" where each release means that a certain amount of actions have been performed in your network to drive controls and risk either up or down
- There is a feedback loop, whereby all the artefacts released by your pipeline can feed back into your functions
Now, imagine if you could deploy such a pipeline by adapting your existing ITSM ticketing tools or workflow automation suites. What if you could actually have a repository where all your operational data is stored as YAML files or similar?
I will leave that to your imagination ;)
Thanks for staying with me this long ;) I hope you enjoyed my musings

