
The Uncertainty of Intelligence and the Entropy of Threats


In Part 1 of this series, we started to lay out the problem space and drew some diėgrams to get a better grasp of them.
However, by merely looking at threat actionability zones we are obviating a very important aspect of threat management: the passing of time. Timely action can be the difference between pwned and not-pwned, between 5 million customer records held to ransom and nothing more than a noticeable event in your perimeter.
In Part 2 of this series, we will explore some eideons that I hope will contribute to developing a new understanding of the mechanics of threat information, intel, hunting and detection.
Threat Intelligence and the Problem of Time
Regardless of the strategic approach you choose to realize the value of threat intelligence, you implicitly work with three different time horizons: threats that could impact us (the future), what can impact us right now based on our attack surface (the present) and what has impacted us already (whether knowingly or unknowingly, the past).

The world is full of potential cyber threats, this doesn't mean they constitute likely threats to your business. Oh! I can now hear some of you going "That's right! So you are now going to talk about the impact and likelihood risk matrix", ehem… no. That would be just repeating what everyone else out there vociferates like automaton robots.
There's nothing wrong with the "likelihood & impact" matrix by the way, but the likelihood of some threat impacting business operations is merely a derived value, the result of a deliberative process that has already decided the final likelihood score. How can you even arrive at that when most Cyber Ops teams struggle to capture the meaningful relationship between potential threats, their actionability gradients and the attack paths they enable in the environment?
Behind this confusion lies the concept of defense-in-depth: interspersed layers of defensive controls like a castle-and-moat model. If one layer is breached, there are additional layers to mitigate risks and prevent unauthorized access.

There is, however, one missing piece in the concept of defence-in-depth. When we think of layers we evoke spatial references, but forget about the temporal layers: past, present and future.

When considering temporal layers on top of our actionability zones we get the concept of threat horizons. A threat horizon brings in the experience of change because the asymmetry of time brings us closer to the reality of irreversible structural changes. If things weren’t changing, it is unclear how we would experience a sense of time passing.
If we had to depict this with a diėgram, using the actionability diėgrams from Part 1, it would look like this (yeah... I know you know I love Excalidraw):

As we saw in Part 1 of this series, one way of thinking about the threats that can/do impact your organization is in terms of their actionability. We formalized this concept in two possible definitions (because we like to embrace ambiguity), here's one of them:
the ability for an organization to articulate decision-making processes based on available information, to direct the actions required for mitigating risk exposure to cyber threats.
The term "actionability" in this context refers to the degree to which a threat that poses a realistic risk to the business can be addressed effectively by an organization. I know what you are thinking: but Diego, you are not addressing the very core of what a "realistic risk" is, aren't we in danger of falling into a circular definition? (i.e. actionability is defined in terms of that which poses a realistic risk; a realistic risk is that which by its own virtue has been identified as actionable)
🔍🤔Well, perhaps this will be disappointing to you but, I am not trying to tell you what constitutes a realistic risk for your business, that's not my job. I am trying to help you understand the ways in which you can produce a threat-informed pipeline of work that is meaningful for your CyberOps. I don't sell those magic pills many vendors promise. In fact, I'm not selling you anything ;) We are co-creating here, I'm helping you carve new patterns of thought that I hope will inspire better ways to solve the usual problems.
Actionability does not care if the threat is within the realm of unrelated possible threats "out there", it only cares about those threats that are likely applicable to your digital landscape given the state of your attack surface. We are not asking ourselves what is the impact and likelihood here. The question we are trying to answer is: should you do something about it, can you do something about it and did you do something about it?
Just because there is a likely threat, it doesn't mean you will do something about it. Even more, just because there is a likely threat, it doesn't mean you can do something about it. Small businesses with very limited budgets certainly cannot afford to do something about every likely threat out there.
Allow me to rephrase the ideas above in terms of could, should, have:

When presented this way, the actionability zones become more clear. There are threats that you could do something about, but this doesn't mean all of them are relevant enough to deserve your attention and resource allocation. However, a subset of the latter are those threats you should definitively do something about, i.e. if you are running Ivanti Sentry and are aware of CVE-2023-38035 with a vulnerability severity rating of 9.8, you should definitively allocate resources to patch, protect and respond to threats in that area.
Despite the above, not all the threats you should do something about are effectively addressed. The reason is simple: there is not an infinite pool of resources at your disposal. You have to prioritize, inevitably. This of course means you will end up doing something about Ivanti Sentry CVE-2023-38035, but may not do something immediately about the 30% of employees who so quickly fell for that phishing simulation, once again.
It does not mean you won't do something about that phishing simulation results in the near future, it just means you have de-prioritized that threat in your present horizon. You may send those employees to their tenth round of phishing training with some boring slides, with a caveat though: only if your organization sustains the awareness about that threat and it doesn't fade away into the past horizon.
There is an important question here, which goes to the heart of this article series: how do we harness the power of our threat intelligence pipeline to maximize the probability of focusing on the right threats? Or to put it bluntly in negative terms: how do we avoid wasting resources on irrelevant threats?
To achieve effective resource allocation for this informational problem, we need to find a way to develop synergistic relationships at every stage of the information processing pipeline between the interconnected systems that consume its outputs and the stakeholders that make decisions based on the data.
One way to make our temporal and spatial layered defences more effective is by building for a specific type of synergistic effect called superlinearity. Amongst other properties, this effect is an aspect of what I've been calling adaptive defence.
Let's explore what synergistic defence-in-depth means in the next few sections, and how can we draw from this idea to engineer better threat intelligence pipelines.
Defence-in-Depth and Superlinearity
Good'ol defense-in-depth, don't we all love that concept? In a way, it helps us picture cyber defence as a series of layered controls and compensating mechanisms that act in unison to neutralize those nasty cyber threats. Phil Venables has an excellent article on this topic (already highlighted by Anton Chuvakin in another piece) where he goes beyond the easy portrait of defence-in-depth and delves deeper trying to clarify what it means. Phil states that:
"... we need to update our notion of defense in depth with a more modern framing... The goal of defense in depth is not just multiple layers of controls to collectively mitigate one or more risks, but rather multiple layers of inter-locking or inter-linked controls"
Further, he indicates that
"If there are N layers then the goal is not just a linear increase in control in proportion to N, but rather super-linear scaling of that effect..."
The concept of superlinear scaling is very apt here and caught my attention. Superlinearity is a condition where a system's response is more than proportional to the input. It has been heavily studied in the fields of computing, engineering and economics.
This is typically illustrated by the multiprocessing capability of modern processors and it's behind the massive success of "the cloud". Parallel computing evokes the intuitive idea that working on a task with parallel processing power decreases the processing time in a linear way: doubling the number of processing units halves the execution time. However, in parallel computing, superlinearity effects show that as the system size grows, each individual processing unit becomes increasingly more efficient, which is a counterintuitive outcome (see here, and here).

(image from: Hadoop Superlinear Scalability)
It must be noted though that superlinearity is a property of a system's response to changes in certain factors, and those factors vary depending on the context. A higher quantity of processing resources is not a universal recipe to achieve superlinearity, in most cases you won't get there by merely scaling computing power. In a more broad sense, superlinearity can be thought of as a metastable phenomenon that relates to information dynamics. It is achieved by the convergence of three dimensions: competitive/cooperative processing schemes, information sharing ratio and network utilization. Too much or too little of either of these variable factors and we might lose the superlinearity effect.

I argue that an effective threat intelligence processing pipeline can produce superlinear returns at an organizational level. Concise but timely and relevant information can irrigate many layers of an interconnected defence-in-depth system. Information about threats can flow into:
Engineering Teams that will perform patching and hardening of systems to mitigate or negate the damage of cyber threats.
Cyber Ops Teams that will deploy new detection rules, update response playbooks and run retro-hunts.
Architecture Teams that will embed new controls in general system design guidelines.
Risk and Compliance Teams becoming more efficient and have more evidence regarding how the security controls work under new threats.
A small input with the right momentum can generate non-linear systemic benefits for the organizational defence-in-depth layers as a whole.
The momentum and the timeliness of threat information are decisive factors that influence the probability of superlinear effects in your defence-in-depth approach. As we saw in Part 1, timeliness is one of the properties of threat information quality. Momentum, on the other hand, is much more intangible and harder to measure. Momentum is a compounding value that facilitates the decision-making process by the concurrent participation of actors that work with the same tempo around an information processing pipeline*.
* This is another important concept for adaptive defence which I won't delve into in this series.
But why is time so important for the synergistic effects of threat information processing and, ultimately, the actionability gradients of threat intelligence collected and analysed by an organization?
The Uncertainty of Information
Why is time important? Because of entropy. Somewhere between 1872 and 1875, Ludwig Boltzmann introduced the idea that entropy (S) is related to the number of possible microstates (W) of a system. He formulated the equation for entropy as S = k ln(W), where "k" is the Boltzmann constant and "ln" represents the natural logarithm. According to this formula, entropy quantifies the amount of information needed to specify the precise microstate of a system. The more microstates available for a system, the greater the entropy and the greater the uncertainty about the system's state.
A classic experiment pertains to the increase in heat for a gas inside a chamber. When heat increases so does the shared energy between the gas molecules, which in turn makes the gas molecules move faster, thus making it harder to predict exact combinations of microstates for the gas molecules within a certain volume.
Another classic example is the different states of molecule arrangements for solids, liquids and gasses as illustrated by different water states. Gas molecules have access to higher numbers of microstates than liquids or solids.

In 1948, a chap called Claude Shannon made an interesting connection between the idea of entropy in physics and the dynamics of information. Shannon posited that entropy is a measure of the amount of uncertainty or randomness in a signal or message. But what does this mean?
Imagine that you want to send the following message this article is a great article, how many bits would you need to transmit that message over the network? Well in a straightforward estimation, if we say that each character requires 8 bits then we need 8 x 31 = 248 bits. However, can we do better than 248 bits?
With natural language, characters and events don't need to be uniformly distributed (evenly spread out). Every language has characters such as e, a or even spaces that occur more frequently than others. When dealing with characters that aren't evenly distributed, what we would like to know is: what is the anticipated number of bits needed to convey a message crafted with those characters?
If we can anticipate an event, then it means this event is less uncertain, i.e. there are fewer chances of a random result. In our sample message, it turns out this is a matter of weighted probabilities of the characters in the message, a metric we can define as a tree by what's known as Huffman Coding, named after David A. Huffman. An optimal coding scheme for this is a great article can be calculated using different approaches but we chose to use a simple online tool like this one:

When analyzing the frequency each character has within this is a great article we obtain the following:
+-----------+------------+----------------+---------+
| Character | Frequency | Bits Required | Size |
+-----------+------------+----------------+---------+
| " " | 5 | 3 | 15 |
| a | 4 | 3 | 12 |
| i | 4 | 3 | 12 |
| t | 4 | 3 | 12 |
| e | 3 | 3 | 9 |
| r | 3 | 3 | 9 |
| s | 2 | 4 | 8 |
| l | 2 | 4 | 8 |
| c | 2 | 4 | 8 |
| g | 1 | 5 | 5 |
| h | 1 | 5 | 5 |
| 96 bits | 31 bits | | 103 bits|
+-----------+------------+----------------+---------+
Total: 96 + 31 + 103 = 230 bits
For sending the above string over a network, we have to send the tree as well as the above compressed code. As we can see, to encode the message using a Huffman encoding we would need 230 bits, less than the original 248 bits. We need less information to describe exactly the same message because we can better estimate the likelihood of each character (event), which means we have less uncertainty involved.
In information theory, information entropy can be used to quantify the amount of information contained in a message, based on the likelihood of each possible outcome. For example, a message that consists of only one possible outcome has zero entropy, as there is no uncertainty or randomness involved. On the other hand, a message that has many possible outcomes with similar likelihoods has high entropy, as there is a lot of uncertainty and randomness involved in predicting the outcome.
So going back to the question at the beginning of this section: why is time important? If we recall the diėgrams in the previous sections, we stated that our main objective is to understand the actionability of information, this actionability decreases the more we look into the future and increases as we approach our present horizon. We called these threat horizons. But why is this the case?
Well, one possible explanation is based on the nature of entropy in information theory: the future is less predictable than the present, and the present is less predictable than the past. The second law of thermodynamics states that the total entropy of an isolated system tends to increase over time, which is why we talk about an arrow of time. In both thermodynamics and information theory, higher entropy implies greater unpredictability or uncertainty about the future state or behaviour of a system. As a system evolves, it tends to explore a greater number of microstates thus making it harder to predict its possible configurations.

In essence, actionability is the inverse of entropy.
Actionability = 1/H
In terms of a system's entropy, higher uncertainty means there is a higher amount of information needed to describe the states of the system (there are many studies that show this, but I really liked this one because I am not a science guy and still found it enlightening). The more microstates there are and the more unpredictable they are, the more information is required, and the more difficult it will be to describe the system.
Intuitively, we know that the world is only getting more uncertain, cyber threats become increasingly more sophisticated and attack surfaces only grow with the development of the Internet of Everything. It is harder to predict hypothetical or emergent cyber threats because there is more uncertainty about the potential configurations of operations that can combine into attack chains. When the first computer program running on an electronic computer appeared in 1948, it was probably very difficult to predict the cyber security risks that would be introduced by AI and Quantum Computing 60 years later.
Is there any way to manage this uncertainty from a business perspective?
Decoding Uncertainty through Threat Intelligence
It turns out there is a way to counter uncertainty and the gradients of risk associated with it in the context of organizational life. To uncover this, we need to go back in time, almost eighty years ago, before the structure of DNA was even described, when the Austrian physicist and philosopher Erwin Schrödinger inspired a generation of scientists by revisiting the fascinating philosophical question: What is life?
Shrödinger was so enthralled by the matter that he actually wrote a book whose title is that very same question. In that book, he suggests that living organisms locally reduce entropy by maintaining highly ordered structures. Organic life achieves lower entropy and higher-order states by spending energy to maintain internal coherence. As Shrödinger puts it in his book "living matter evades the decay to equilibrium". But how? It would seem that there is a little thing called metabolism that helps us living entities evade this decay:
All known organisms consist of one or more cells, the most basic units of life. Each cell maintains a precise and constant internal physiochemical environment throughout its life that is distinct from its surroundings. This is achieved by expending energy acquired from externally derived nutrients (free energy) to fuel diverse regulatory processes that are collectively termed “metabolism”. Therefore, organisms, and the individual cells that compose them, are open systems that continually exchange nutrients and wastes with their environment. In effect, all organisms maintain their low entropy status by “eating” free energy and “pooping” entropy. (Schreiber, A., Gimbel, S. Evolution and the Second Law of Thermodynamics: Effectively Communicating to Non-technicians. Evo Edu Outreach 3, 99–106 (2010)
(Uh yeah... I just quoted a text that mentions 💩 and put it in an article about cyber stuff. Most 2yo and 3yo would celebrate my rebellious expression of art! I could keep on digressing about this but alas! poop time is of the essence!)
Now let us ask ourselves the following question: what is the embodiment of a threat to the internal coherence and ordered complexity of living organisms? The same thing that causes snotty noses 👃🏽 in winter: a virus 🦠
There is a reason why the most basic and naive representation of a cyber threat is a "computer virus": they represent a disruptor of digital systems in the same way their biological counterparts are of living ones.
Biological viruses are interesting entities, they exist in both an inert state called virion and an active "live" state called the virocell. Virions are complete viral particles in extracellular form, they are like "spores" and lack the cellular machinery for independent replication, they must hijack a host cell to express their encoding and turn regular cells into virocells.
We can generalize this concept to cyber threats too. Digital threats have an inactive phase, the threat, and an active phase which is the attack. A threat is in a way like a virion that has not yet manifested into an attack by hijacking an organization's resources. Once these resources are hijacked (either by depleting them in the case of a DDOS attack or by achieving remote code execution), the attack tends to replicate (move laterally) and eventually capture and exfiltrate information that can damage an organization's integrity.
Viruses are also entropic drivers for disease and cancer evolution by increasing the number of possible microstates available to the host cell, thus favouring mutations. The same can be said of cyber attacks, they are entropic drivers that alter, abuse, disrupt, degrade, or destroy the coherence of computer systems or information. We say a cyber attack has occurred when there is evidence of material damage to an organization. However, with threats, this damage is not yet actual: it has not yet crystallized. Cyber threats are the statistical representation of attacks: not real but potential attacks with varying degrees of likelihood. Cyber threats are unrealized attacks that have not yet caused actual damage.
We can define cyber threats as sequences of operations that carry the potential to disrupt informational coherence inside organizations. Future threats are harder to predict, the further away from the present horizon, the more unpredictable they are, and more information is required to understand (describe) them.
In this context, threat intelligence is an attempt to produce information that describes the actions involved in carrying out cyber attacks. The more descriptive this information is, the more coherent datapoints we have about threats, the higher our ability to protect our business from them.

But future threats are not the only source of disruption to businesses and institutions. Current, unprocessed information in our present horizon is also highly entropic. Not having a proactive stance towards the understanding of the present threat landscape simply means your organization lives in a sea of unknown threats: higher quotas of untamed uncertainty.
The threat intelligence process reduces informational entropy. In the process of producing information about potential threats, a threat-intel pipeline reduces the uncertainty about them. A properly implemented pipeline should have the ability to decode the many features of threats and map those out to your organization's attack surface: capability, danger levels, impact and likelihood, actionability, attach chains, etc.
In this context, actionability can be considered as a measure of how uncertainty of information with low levels of usability can be metabolized into usable information. The process of bringing a threat under governance is a process of local entropy reduction by which a potentially disruptive state (threat) is modulated in terms of security controls. 💉
Latent Space and Detection Engineering
As threat hunters and detection engineers, we care about capturing the "genome" of a threat into a codified form that can be identified by our protective systems. However, a full genome can sometimes be unnecessary and computationally heavy.
* 🤔 intentional mental note: I could have simply just said that we like to "create detections" instead of the above long sentence... yet again isn't this whole essay a long thing? and why would I write even the shortest sentence to repeat what everybody already knows? Anyway, sorry for the time wasted with this snippet of internal monologue. 😅
Shannon's key insight is that predictable information can be compressed more efficiently. Fewer symbols are required to represent the original message. This is also the ultimate goal of CyberSecOps: to encode threats as efficient information within an organizational system. Information is compressed by encoding it within predictable patterns.
When engineering an analytic like a detection for a threat, we are effectively describing the threat with less information. From a huge threat report containing thousands of words about the TTPs of a particular threat actor, we derive detective controls that are machine-readable and translate our knowledge about the threat into a simpler and more interoperable representation.
In the machine-learning realms, this is what's called latent space.
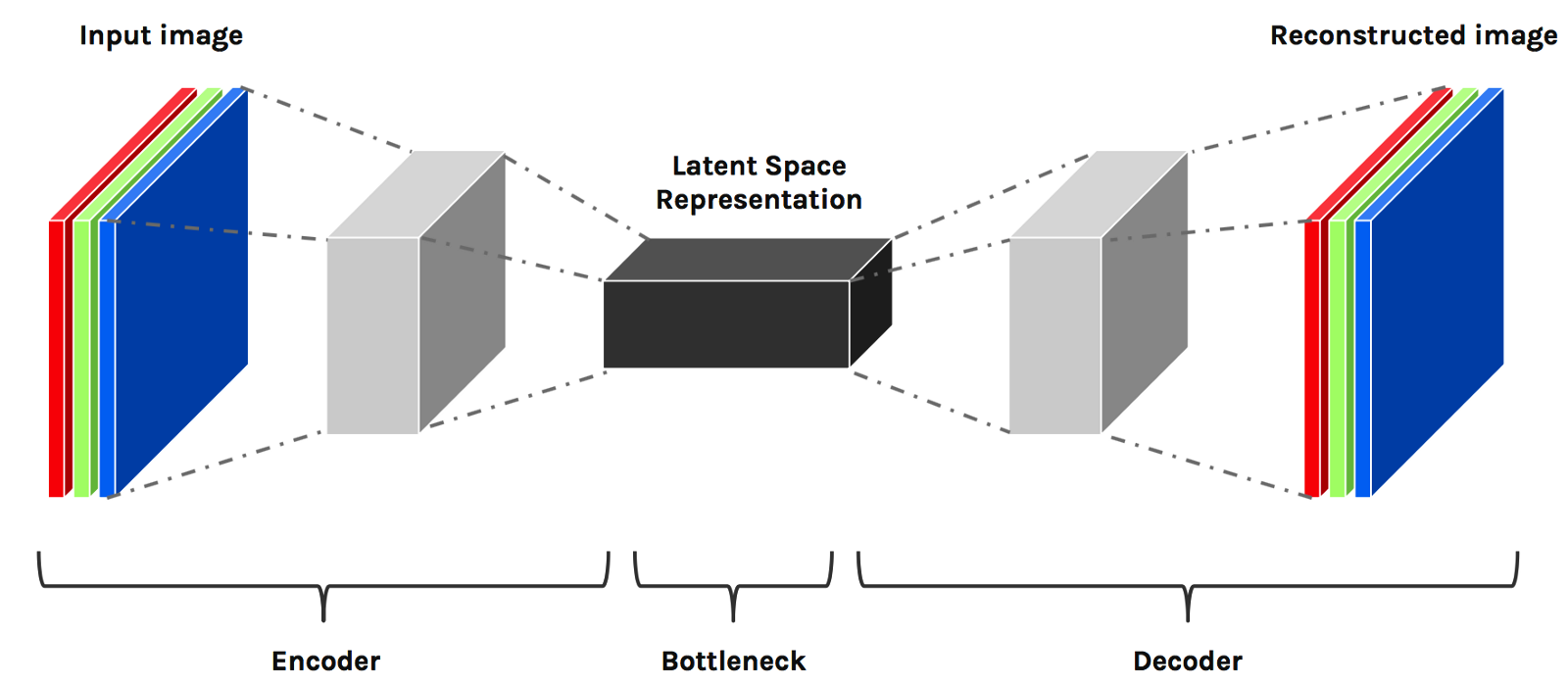
(Image from Hackernoon)
I am not a machine learning virtuoso -well not even a proficient one really-, but I think latent space is an apt model to describe what are are trying to achieve when developing detections.
Latent space is a lower-dimensional representation of information that captures essential features of the input data. Jared Atkinson has implicitly elaborated on this idea through his series On Detection: Tactical to Functional. If you have not been following that series: you should. Trust me, the two research streams that have contributed groundbreaking ideas to the world of detection engineering and hunting are the SIGMA project and Jared's On Detection series. In Part 6: What is a Procedure?, Jared very well summarizes the essence of the series in that he has expanded our understanding of the map we use to navigate the territoire:
Imagine that we have been trained our entire career to view the cyber world through a three-layered lens (Tactics, Techniques, and Procedures). As a result, we apprehend the cyber world as something composed of three layers and tend to be limited to thinking and talking (but I repeat myself) about it within this three-layer construct. Through this blog series, I have attempted to shed this preconceived structure to explore the ontological structure of this world, or at least estimate it as well as I can. The result has been interesting for me, and I hope for you as well because we have discovered the existence of at least six layers (functions, operations, procedures, sub-techniques, techniques, and tactics)
Latent space is about the map that a machine learning model "learns" in order to navigate the higher dimensionality of the original information space. Engineering detections is in a way a similar process, by which we try to abstract the complexities of an attack chain and focus on the most important aspects of it. These abstractions happen at various levels, like the six levels from SpecterOps 🔍. This is what the MITRE Project tries to capture as a knowledge graph. Detection logic or "detectors" are always a lower dimensionality representation of the rich complexity of a threat 📊.
In this sense, detection engineering is the process of understanding the layers that compose a behaviour and the descriptive parameters that best apply to each layer. Engineering detections is also about finding those patterns that constitute the lowest common denominators leading to "choke points" and minimizing the information needed to capture the highest amount of threats of the same class (same procedure or same operation for example)
Delving deeper into this topic would require a whole other article which is not intended for this series. In our next article, we will explore how can we engineer a threat information processing pipeline based on the core aspects of how information becomes actionable: network dynamics and the discovery chain.
Digestif
Hey guys, if you stuck with me all the way through to this point: I salute your potent attention and focus skills! In today's short-content-rules world, it is hard to find fearless warriors who can read past a twitter-length post.
To thank you for your incredible determination in our quest for active defence and beyond, allow me to share with you some inspiring things that have happened over the last three weeks:
Wim Hof. Inspiring Change.
I woke up one day with a terrible stiff neck, I couldn't work. All I could do was sit in weird positions and watch documentaries. I was blessed enough by the algorithm gods to get a recommendation for The Mulligan Brother's Short Doco Big Pharma VS Wim Hof | Mulligan Brothers. It's 30 minutes packed with incredible insights and a window into Wim Hof's deep pain that helped him transform himself and so many others on this planet by learning the art of the cold.
What the hell does that scatterplot mean?
I love data visualization but I always struggle to understand what's the best way to represent the data at hand. For some reason, the filtering alleyways of the internet lead me to data-to-viz.com where I can browse different visualization models and understand their caveats and where they shine!
Advancing the state of the art in Detection Engineering
There are two ripples in the detectivesphere that truly advance the state of the art in the detection engineering space, one is relatively old -by today's cyber standards where yesterday was already a century ago- so its voice has been maturing for the last few years. I am talking of course about the SIGMA project with all the latest from Nasreddine Bencherchali like the new SIGMA Website.
The other hugely transformational insight into the detectivesphere is Jared Atkinson's Series of "On Detection: Tactical to Functional". I have been following the series since its inception and recently read Part 11. I love the clarity of the concepts exposed and how this series keeps on building from one idea to the next, in a movement that is creating dynamic new ways of understanding the art of detection engineering. There is deep knowledge in the realization that the classical layers of attacker behaviour (tactic, technique, procedure) can be further broken down into more atomic and less stable states. Quantum leaps.
Someone is noticing ThreatHunterz
Zach "Techy" Allen DetectionEngineeringWeekly 47 mentions our previous post. We would like to thank Zach for the brave mention, I highly recommend subscribing to his newsletter for the latest news and how-tos in detection engineering!
How to do great work
I found a gem of the indie bloggosphere: How to do Great Work by Paul Graham. This guy seems to have collected and analysed the patterns that people who do great work in any field develop. I am not talking about the vacuous coach-style self-growth-guru-like article, this is nothing like that, I am talking about a unique literary piece with an exquisite mix of an engineering approach, fresh thought and easy-flowing style.