
🔮R1D3 Threat Driven Research Pipeline - Part 2
Extracting Actionable Insights from Threat Data


Today, let me start with a bit of confession time: my quest to build an "Active Defense" framework has led me down a rabbit hole of epic proportions even the wisest tech oracles wouldn't have predicted 🐇🕳️🔮.
A simple pondering of questions about the shortsighted views around Detection Engineering vs Threat Hunting motivated me to outline something called the R1D3 Framework (Research -> Discovery -> Disruption -> Development) which in reality is an evolution of the ideas discussed in The Threat Hunting Shift series. Ideas that somehow materialized in AIMOD2 but were not yet quite articulated.
“Where the heck is your Framework man?” This is a valid question you may ask. To that I would answer: you are witnessing it as it unfolds. You are looking at it with all the chaotic ideas colliding to create new connections, with all the imperfections... ✨💥

This is a journey, folks. A journey to find the hidden signal in the noise, the actionable insights buried within the chaos. There is something here I cannot yet fully understand but has a lot of potential, I'm exploring it and applying this practically as I go 🗺️. One day, there will be a book about this and you will say “Oh! I know that bloke, he used to write weird sh*† about active defence”.
In Part 1 of our R1D3 Threat Driven Research Pipeline, we dove headfirst into the messy world of practical threat intel research. We laid out the foundations of what a Research pipeline looks like to deliver some meaningful and actionable content to the rest of the RIDE streams⚙️. The diagram?
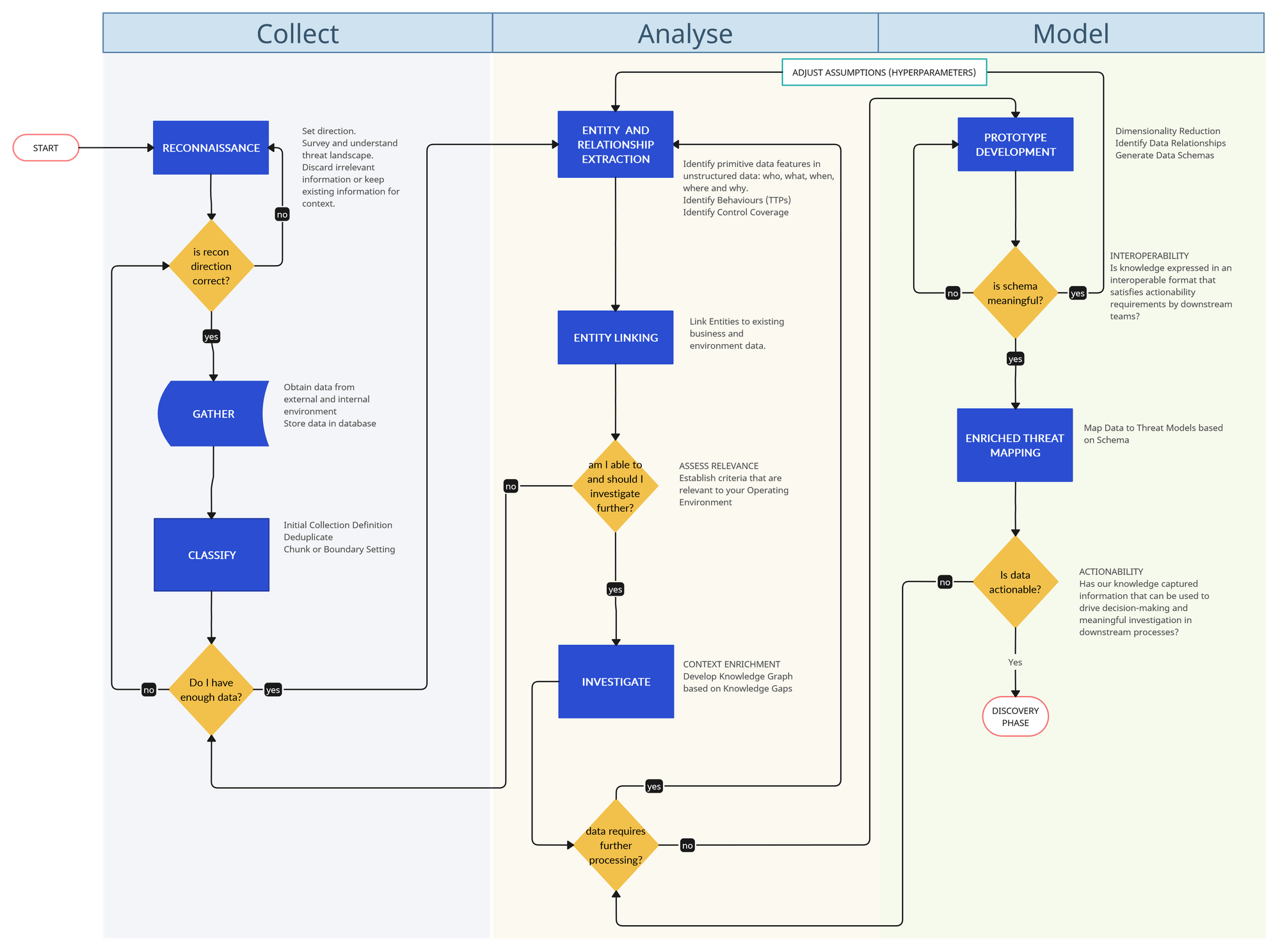
By now you know that the Research phase of RIDE does not focus so much on how and where your information is sourced from, but looks at extracting actionable information for operational discovery and disruption processes further down the road.
The big question swirling in my head: what does all this data really mean for my organization? 🤔 It's a battle of brains vs. machines – we need info that machine algorithms can't easily digest whilst also being easily scalable and structured. Apparently, the true enemy isn't some shadowy hacker, but how we understand threat data, how we collate all of that, process it, build semantics around it, produce data models with it and ultimately influence security control uplifts.
What am I even talking about? 🤔😁 This whole process feels delightfully experimental 🧪. Let's call it... iterative chaos. Results may surprise us all! But if you are looking for certainty and easy-to-digest stuff please don't listen to my shenanigans! I advise seeking solace in classic industry knowledge with known buzzwords and predictable plots.
Without further ado, in this article, we will expand on the Analysis phase: Entity and Relationship Extraction, Entity Linking, a Filter Question (am I able to and should I investigate further?), and how to build our knowledge graph from our knowledge gaps.
Analyse 🧪
Step 04: Entity and Relationship Extraction 🕸️
Up to this stage, our data exists very much still in an unstructured shape. We have performed some very coarse initial classification by applying metadata tags and have set some boundaries around what belongs to the same body of work and what should be considered an independent one. Work done so far constitutes our first pass over the data and has generated a metadata layer, but we have not yet extracted meaningful information from our sources.
We now need to perform a second pass over the data to develop an initial semantic layer over it and convert this data into a first information layer. The backbone that will sustain this new structure is the identification of relationships and entities that are useful for our purpose. Depending on your approach to the pipeline design, you will be implicitly or explicitly defining the first few elements of a knowledge graph, i.e. extracting nodes (aka vertices) and edges (aka relations).
Initially, our unstructured open-ended questions will drive what gets identified as an entity and what doesn't, but as our research pipeline algorithm feeds from the late modelling phase back to the analysis phase, it will begin to highlight the entities that have the richest meaning and highest descriptive power in our downstream processes. We are effectively building a self-learning knowledge graph.
As an example, let's consider this extract from Microsoft's article on Volt Typhoon:
To achieve their objective, the threat actor puts strong emphasis on stealth in this campaign, relying almost exclusively on living-off-the-land techniques and hands-on-keyboard activity. They issue commands via the command line to (1) collect data, including credentials from local and network systems, (2) put the data into an archive file to stage it for exfiltration, and then (3) use the stolen valid credentials to maintain persistence. In addition, Volt Typhoon tries to blend into normal network activity by routing traffic through compromised small office and home office (SOHO) network equipment, including routers, firewalls, and VPN hardware. They have also been observed using custom versions of open-source tools to establish a command and control (C2) channel over proxy to further stay under the radar.
We could break down this information into the following rudimentary schema, bear in mind that this step can either be performed by LLM models or by the analyst:
entities:
- type: threat_actor
name: Volt Typhoon
- type: technique
name: living-off-the-land (LOLBins)
- type: technique
name: hands-on-keyboard activity
- type: tool
name: command line
- type: data
name: credentials
- type: data
name: archive file
- type: device
category: SOHO network equipment
examples: [routers, firewalls, VPN hardware]
- type: software
name: open-source tools (custom versions)
- type: protocol
name: proxy
relationships:
- actor: Volt Typhoon
action: emphasizes
target: stealth
purpose: evading detection and increasing chances of achieving objectives
- actor: Volt Typhoon
action: relies on
target: living-off-the-land techniques
purpose: achieve mission objectives
- actor: Volt Typhoon
action: relies on
target: hands-on-keyboard activity
purpose: achieve objectives
- actor: Volt Typhoon
action: issues commands
target: data (specially credentials)
purpose: data theft
- actor: Volt Typhoon
action: stages data
target: archive file
purpose: preparation for exfiltration
- actor: Volt Typhoon
action: uses
target: stolen credentials
purpose: maintain persistence
- actor: Volt Typhoon
action: routes traffic
target: compromised SOHO network equipment
purpose: blend into normal network activity
- actor: Volt Typhoon
action: uses
target: custom versions of open-source tools
purpose: establish command and control (C2) channel
On the first few iterations of our research pipeline, we may extract these simple entities and relationships like "device" or "threat actor", however as we iterate and feedback from our explicit modelling stage, we will become better at describing richer relationships and discarding irrelevant data. For example:
we might take a shortcut into early extraction of MITRE ATT&CK TTPs with varying degrees of granularity
in future iterations we may not find certain features relevant to our process anymore:
perhaps we don't care whether the threat actor acts with "stealth" since this is normally an easy assumption, who wants to be discovered before achieving mission objectives?
we know that the majority of threat actors will want to "stage" data for exfiltration, so perhaps we want to be more granular and identify specific procedures early on
we may add properties like timestamps, data provenance and risk-scoring metrics to each of the entities
we may enrich our data with prevalence scores of each entity or relationship, and even add potential impacts to an organization that naturally follow from the threat
Step 05: Entity Linking
Once we have extracted initial entities and their primitive relationships, we have to link them to pre-existing entities in our environment that constitute relevant datapoints. This will be important in deciding whether anything here deserves further attention:
Do any of the identified technologies exist in our CMDB?
Are the threats potentially affecting assets in the cloud or on-prem? If cloud, which cloud providers, zones, areas, resource groups?
Are any of our crown jewels linked to or running services potentially impacted by identified threats?
Are there current security controls that mitigate these threats? These security controls can be protective, detective, corrective, etc.
Have we observed internal vulnerabilities that are linked to the threats or exploits identified in the information at hand?
Have we observed incidents, alerts or notable events that can be linked to the threats we have identified?
Entity linking is the process by which extracted data is linked to existing aspects of our unique digital landscape, this allows us to create connections that are meaningful within the environment in which we operate. Not every environment is the same, not all technology stacks behave equally, not all industries are exposed to the same threats, and not all cyber security teams are equally mature, nuances matter here.
Step 06: Am I able to and should I investigate further?
Based on the knowledge we have built from our research pipeline so far, we are now in a better position to determine the relevance of the information at hand. This is the third of six filter questions we ask ourselves along the way. A process without filter questions is a recipe for wasted time and effort.
There are two key questions we must ask ourselves at this point:
the first thing we need to ask ourselves: is this information relevant to my operational context and does it enable me to continue my investigation? We are trying to ascertain whether the information we have developed so far indicates any threats to our running operational environment, i.e. our business context, digital infrastructure, etc.
the second question is very simple: should I continue investigating further? What we are trying to find out is whether we should dedicate further resources to prepare this information for actionability by downstream processes.
To determine whether we are able to investigate further is to define a set of criteria that are meaningful to our business vertical or operation. These criteria cannot be decided abstractly as they will be unique to your operational environment, but there are some commonalities we can point out:
do the threats identified in the information relate to technologies our business operates with?
what kinds of threats is our organization mostly concerned about? do they roughly match the ones we have identified thus far?
what is the prevalence of the threat or threat actor in our region, industry vertical or business?
what is the criticality of the threat in terms of ease of exploitability, zero-day or already known, existing offensive tradecraft, etc?
If we have a reasonable belief that the threats outlined so far likely apply to our digital landscape with a medium to a high degree of confidence (these thresholds are up to you to experiment with), but we don't fully understand how that threat may impact our operational environment, we have a knowledge gap that means our attack surface might be exposed to high risk. This risk and the unknown elements of our knowledge about it may justify our engagement in downstream processes. If this is the case, we will then flow into the next stage: investigate.
The biggest difference between the investigative stage and all the previous ones in our research pipeline is that we can essentially automate all the prior steps but we cannot automate the investigation. The next stage requires all the power of human analytical brains, automation can aid in extracting information for analysis, but the analysis has to be done by a threat analyst in the end.
What happens if data is not relevant or I determine no further investigation is required?
We may have reached this point and realised that the data we have is either not relevant to our operational environment or we've collected enough datapoints to decide that these threats don't pose a significant risk to our business, despite their relevance.
This might be due to a few factors, but the most important ones that can help decide our relevance score are: have we actually collected enough data and is our reconnaissance direction correct? If our recon does not need calibration, then it's a matter of collecting further data, and going through our entity extraction and linking again. If our recon direction was not correct, then we might need to decide whether we need to discard the information obtained and processed so far or simply correct our course and continue gathering.
It's important to understand that "it is much better to delay the final analysis than to provide an assessment that the analyst knows is flawed" (Intelligence-Driven Incident Response, p42)
Step 07: Investigate: Develop your Knowledge Graph from your Knowledge Gaps
Analysis, as much an art as it is a science, seeks to answer the questions that were identified in the Direction phase (Intelligence-Driven Incident Response, p41)
Up to this point, we have produced information by extracting relevant datapoints and links from available data. All the steps leading up to the investigative stage can somehow be automated or are easier to "DevOpsify" if that is even a word. Our investigative stage though can be as complex as necessary and requires the type of cross-functional, multidomain, context-aware and nuanced understanding of us humans. The principle that guides the investigative stage is simple: Develop your Knowledge Graph from your Knowledge Gaps. These gaps are like missing links, missing nodes, or unconnected dots that need to be somehow related to our existing knowledge graph. For example:

At every point of our research pipeline, you will notice the play between a more high-level eagle-view and a more detailed ground-level view. R1D3 recognizes the dynamics of high-level vs low-level, abstract vs concrete, and exploration vs exploitation patterns. By extracting entities and linking them with useful relationships to themselves and to entities in our environment, we develop a map of relevant datapoints that provide insight into what matters and what doesn't.
Our purpose is to transform data from its raw form to an actionable form. By "raw" I mean data that can either be in structured or unstructured shape, refined or un-refined, but whose existing structure so far does not allow the cyber function to drive the mechanics of risk reduction. Information is just information. What you can do with it is a whole different matter.
We now have information that is highly relevant to our active defence pipeline, but there is a lot we don't know yet:
we may have failed to properly link our data to relevant security controls
we may not yet fully understand whether we have observed the attack patterns identified so far within the thousands of notable events, alerts or incidents that triggered over the last 12 months
we may actually need more granular information like the actual procedures or operations by which credentials can be dumped from a Windows 11 host, instead of less rich, higher level MITRE techniques
perhaps we want to identify existing defensive or offensive tradecraft leveraged in the wild (open and closed source projects, Git repos, etc.) and understand how they work
perhaps we have been asked to develop trend visualizations of the threats extracted from our research pipeline and need to collect historical data
it might be needed to investigate current and past Pentest, Red Team or Purple Team engagements to understand what gaps have been closed, which ones still remain, and how these relate to our knowledge of extracted threats so far
we might want to reverse-engineer malware samples or dynamically run them through a sandbox to understand how they work
Whatever your knowledge gap is, you need to delve deeper now into specific aspects of your information and develop your knowledge graph further. By knowledge graph I mean an implicit construct in your mind or an explicit graph database you populate at each step, this is up to you.
Next Steps
The information refinement that has taken place so far has been strongly surfaced by implicit models and schemas, things that live in the brains of intel or security analysts but have not been explicitly defined to sustain the test of higher OODA loops and scales. To unlock the full potential of your threat research, you need to transform this raw information into actionable models. Think of it like building a blueprint, where scattered data becomes a structured plan. In the next part of the series, we'll explore an aspect of threat research that many hunt, detection engineering, incident response and SOC teams usually ignore and don't think about much.
Until then, I wish you all a great week, stay tuned and drop me your comments below!